On the Estimation of Treatment Effect with Text Covariates
本文发表于2019年IJCAI会议。
Introduction
Treatment effect,是指一个变量(treatment)对另一个变量(outcome)的作用,定义为对treatment进行干预后结果的改变。 本文是研究用文本协变量(textual covariates)估计treatment effect。所谓协变量是一个独立变量(解释变量),不为实验所操纵,但仍影响实验结果。不同于数值型协变量,文本型协变量受到的关注更少而且包含更多信息以及层次(word level,topic level,semantics level)。文本数据的这一特性给文本协变量的处理效果估计带来了新的挑战。特别是,一些文本协变量对treatment assignment有很强的预测作用,但对outcome却没有那么大的预测作用,这种协变量被称为nearly instrumental variables(近工具变量)。现有的工作已经表明,对nearly instrumental variables的调节往往会放大因果效应分析中的偏差。因此,在评价treatment effect时应将其排除。然而,当协变量包含文本数据,re-weighting或feature selection based approaches将是有限的,因为这些方法只能被限制在一个特定级别的信息文本中包含的变量,从而不足以总结文本的协变量,进一步导致不足以过滤掉nearly instrumental variables。
Preliminaries
首先我们定义一些符号:
- W:treatment。假设数据集中有N个records,$W_i$是第i条records的treatment。
- X:non-textual covariate。
- T:textual covariate。$T={T_1,T_2,..T_N}$,$T_i$属于第i条记录,$T_i=[t_{i,1},t_{i,2},…,t_{i,N_{t_i}}]$,$t_{i,j}$是第i条记录的第j个单词。
- $Y^w_i$:第i个records的用第w个treatment的潜在结果。
- $Y^F$:观察结果。
仍然遵循potential outcome framework和假设(Stable Unit Treatment Value Assumption,Consistency,Ignorability,Positivity),以确保治疗效果可以确定。最后,整个问题的输入输出定义如下: - input:非文本协变量X,文本协变量T,treatment assignment W和观测结果$Y^F$
- output:ITE( individual treatment effect),ATE(average treatment effect),ATT(average treatment effect on the treated group)。利用上述假设,他们定义如下:
$ITE_i=E[Y^1|X=x_i]-E[Y^0|X=x_i]=Y^1_i-Y^0_i$
$ATE=E_U[Y^1-Y^0]=\frac{1}{|U|} \sum_{i \in U}(Y^1_i-Y^0_i)$
$ATT=E_{U_1}[Y^1-Y^0]=\frac{1}{|U_1|} \sum_{i \in U_1}(Y^1_i-Y^0_i)$
Methodology
作者提出的 conditional treatment-adversarial learning based matching method (CTAM)的框架如下所示: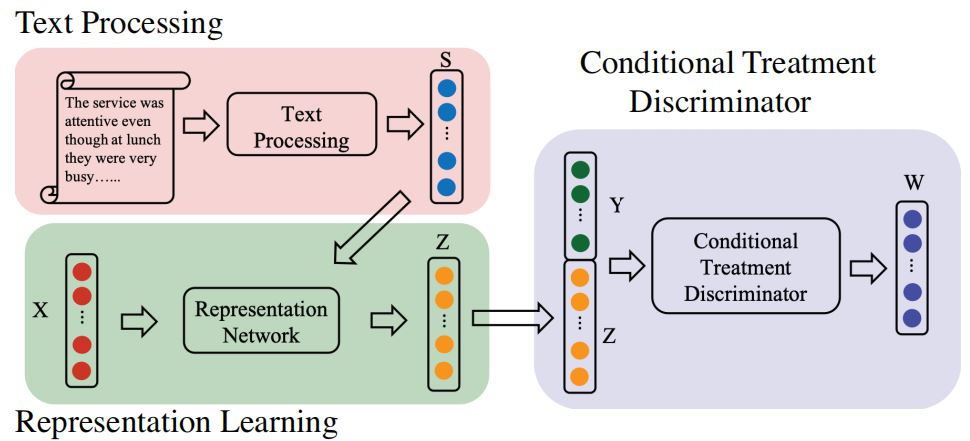
如图所示,CTAM包含3个主要组件:text processing, representation learning, and conditional treatment discriminator。通过text processing组件,将原始文本转换为矢量化的表示形式S,然后将S与非文本协变量X连接,构造统一的特征向量,并将其输入表示神经网络,得到潜在表示Z。学习表征后,将Z和可能的结果Y输入conditional treatment discriminator。通过阻止鉴别器分配正确的处理,representation learning可以过滤掉与nearly instrumental variables相关的信息。最后的匹配过程在表示空间Z中执行。
Text Processing and Representation Learning
文本的数值表示是将所有词的词向量进行平均(有点粗糙),得到S。然后将S和数值型协变量X拼接成C,利用一个表示神经网络(实际中,由一个带RELU的 feed-forward neural network来实现)来得到latent representation Z,$Z=\Phi_{rep}(C;\Theta_\Phi)$。然而Z包含nearly instrumental variables的信息,接下来说明如何处理这一问题。
Conditional Treatment Discriminator and Conditional Treatment-Adversarial Learning
- Conditional Treatment Discriminator:输入为Z和potential outcome Y,输出为treatment assignment W。在conditional treatment discriminator的作用下,学习后的潜在表示可以消除treatment assignment的conditional dependency。conditional treatment discriminator是一个 feed-forward neural network,定义为$D(Z,Y; \Theta_D)$,其中$\Theta_D$是其参数。目标是正确的预测treatment assignment。损失函数为交叉熵损失,定义为:$L_D(\Theta_D,\Theta_\Phi,\Theta_\Psi)=E_{(c,w)~(C,W)}[-logD(\Phi_{rep}(c;\Theta_\Phi),\Psi_{pop}(\Phi_{rep}(c);\Theta_\Psi);\Theta_D)]$。我们来解释一下这个损失函数,$\Phi_{rep}(c;\Theta_\Phi)$就是$Z_c$,$\Psi_{pop}(\Phi_{rep}(c);\Theta_\Psi)$是pseudo outcome predictor with $\Theta_\Psi$as its parameters。我们将在下一部分介绍这个。
- Pseudo Outcome Prediction:conditional treatment discriminator需要所有treatment的potential outcomes,表述如下$Y=\Psi_{pop}(\Phi_{rep}(C);\Theta_\Phi)={\Psi_i(\Phi_{rep}(C);\Theta^{(i)}\Phi)}^{n_w}{i=1}$,$\Psi_i$是每种treatment的预测结果。
- Conditional Treatment-Adversarial Learning:conditional treatment-adversarial learning的目标就是过滤掉和nearly instrumental variables相关的信息。由于nearly instrumental variables指的是对treatment assignment比outcomes更有预测性的变量,因此这种过滤策略相当于去除潜在表征和treatment assignment之间的条件依赖性。为此,我们训练了一个对抗学习模型来实现这一目标。判别器D试图最小化损失L来给出正确的treatment,而$\Phi_{rep}$ 和 $\Psi_{pop}$将最大化这个损失来过滤掉这个信息。当 conditional treatment discriminator被成功地欺骗时,nearly instrumental variables相关的信息可以被成功过滤掉。
Loss Function and Parameter Training
- loss function:最终的损失为$L=L_p-\lambda L_D$,其中$L_P(\Theta_\Phi,\Theta_\Psi)$它是group distance和pseudo outcome prediction损失的总和,定义如下:

The first term in measures the pairwise distance between the records sharing the observed outcome label under the same treatment, and the second term measures the pairwise distance between the records that have different observed outcomes. Minimizing the difference of two terms makes similar records close to each other, while dissimilar records far from each other in the representation space. The third term is the pseudo outcome prediction loss, and minimizing it allows better potential outcome predictions for conditional treatment discriminator. - Model Training:

- Nearest Neighbor Matching

Experiment
Evaluation Metrics
有以下几个评价标准:
- PEHE: precision in estimation of heterogeneous effect,$PEHE=\sqrt{\frac{1}{n} \sum^n_{i=1}(ITE_i-ITE’_i)^2}$.
- $\epsilon_{ATE}$:error of ATE estimation,$\epsilon_{ATE}=|ATE-ATE’|$
- $\epsilon_{ATT}$:error of ATT estimation,$\epsilon_{ATT}=|ATT-ATT’|$
Dataset
- News Dataset(Johansson et al.,2016):The News dataset studies the effect of viewing devices to the user experience.
- IHDP Dataset(Brooks-Gunn et al., 1992):This dataset is from the Infant Health and Development Program targeting low-birth-weight, premature infants.
- CFPB Dataset([Egami et al., 2018): The CFPB solicits complaints from consumers across a variety of financial products and then addresses those complaints.
